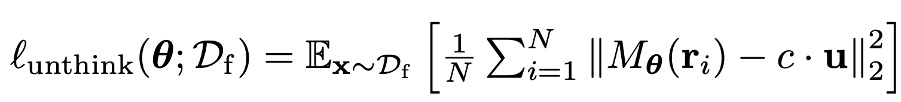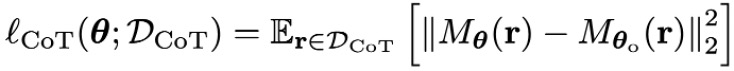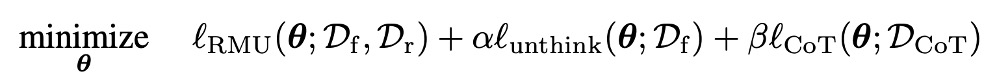Can Existing Unlearning Adapt to LRMs?

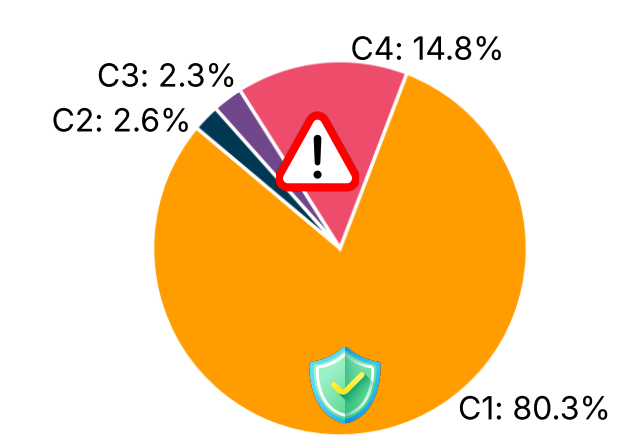
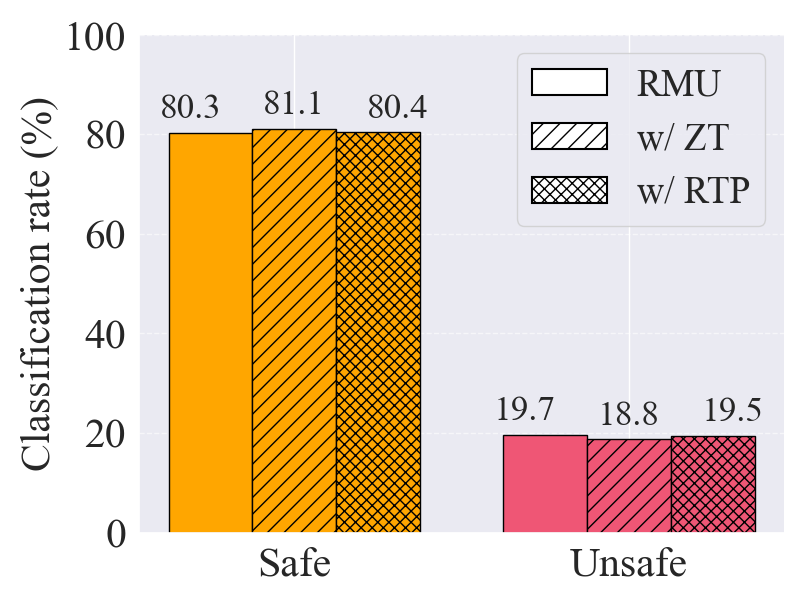
Figure: Demonstration of LRM unlearning challenges.
-
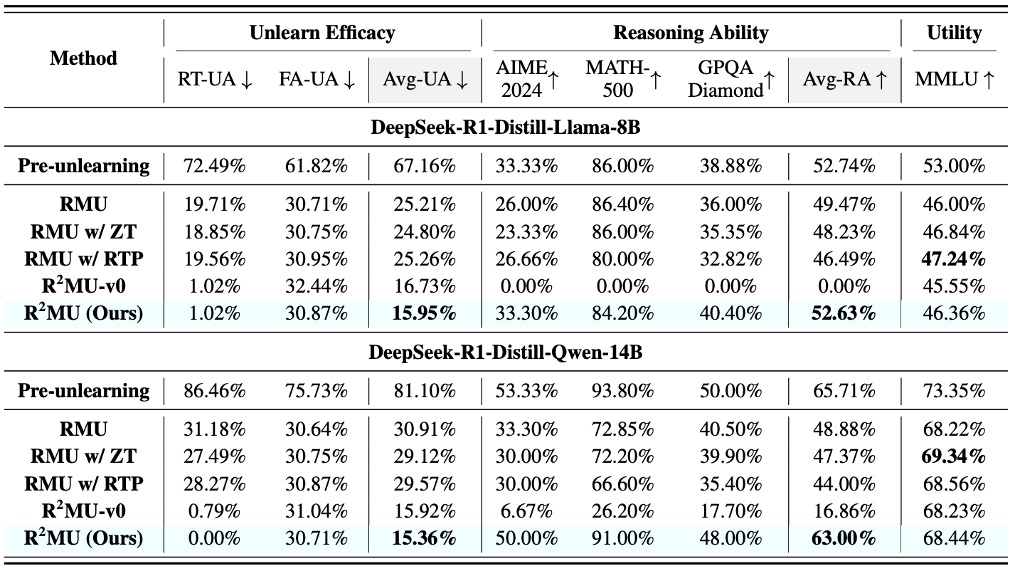
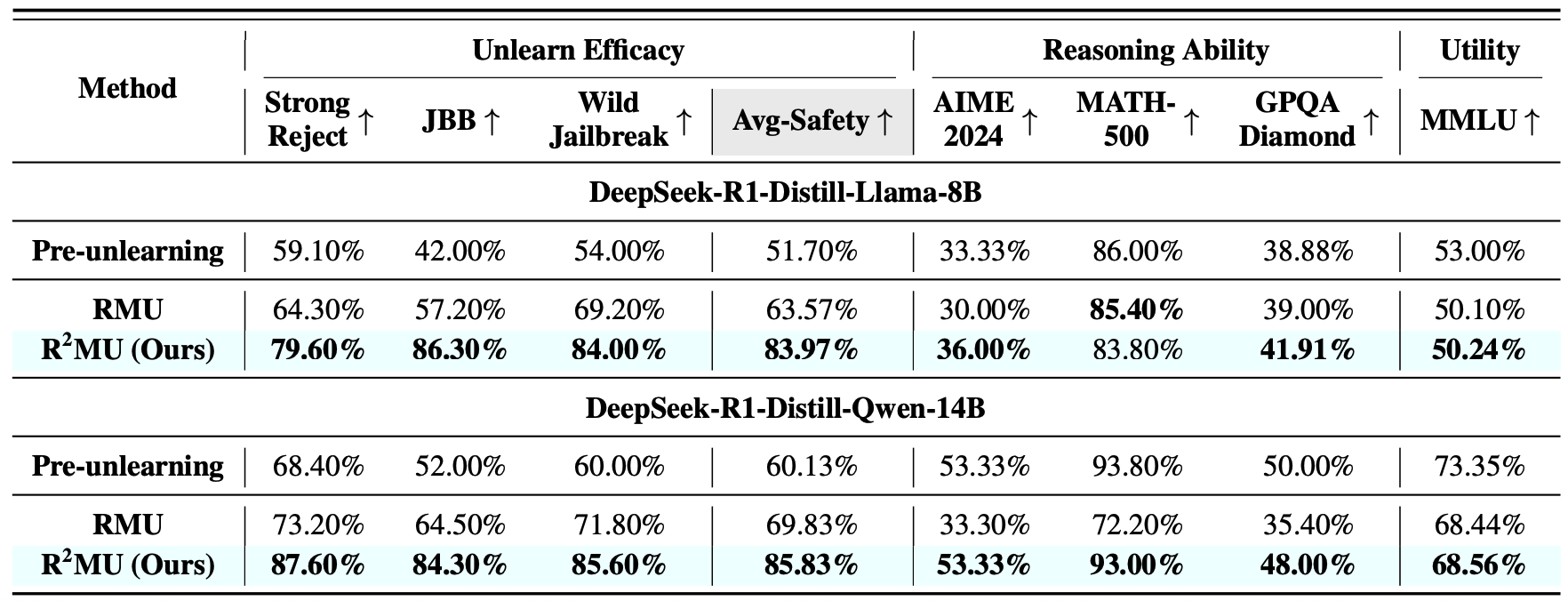
Challenge I: Existing unlearning fails to “unthink.” Current unlearning methods effectively sanitize final outputs but fail to eliminate sensitive information embedded within the reasoning traces of LRMs.
-
Challenge II: Degradation of reasoning ability. Current unlearning methods substantially degrade the reasoning capability of LRMs.